CPT’s Mark Spivak, functioning as a research consultant in conjunction with Emory University’s Neuroscience Department, co-authored a fifth research paper published in a prestigious peer reviewed academic journal. The article, entitled “Awake fMRI Reveals a Specialized Region in Dog Temporal Cortex for Face Processing,” co-authored by Dr. Daniel D. Dilks, PhD, Dr. Peter Cook, PhD, Samuel K Weiller, Helen P. Berns, Mark Spivak, CPT, and Dr. Gregory S. Berns, MD, PhD, describes the existence of a fusiform face area (FFA) within the canine brain.
The FFA, which in humans is located in the fusiform gyrus in the ventral surface of the temporal lobe, is responsible for identifying and processing facial visual information. The FFA is highly relevant to interpersonal communication. People with damage to the FFA will suffer from a condition called prosopagnosia (face blindness), where the affected person will see faces, but cognitively lack the ability to recognize the faces.
Until the publication of the Emory-CPT paper, the existence of an FFA had never been confirmed in dogs. Yet, dogs use facial countenance as an important component of dog-dog and dog-human communication. Moreover, dogs are social pack animals, where identification of faces may be highly relevant to discriminate pack members from interlopers. Most importantly for practical purposes, knowledge of the canine FFA, its operation, and its activation may lead to improved human-dog communication protocols and improved working and pet dog training methodologies.
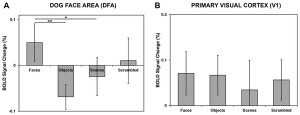
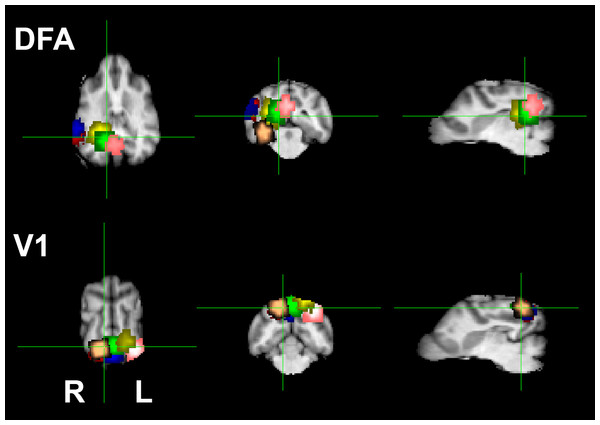
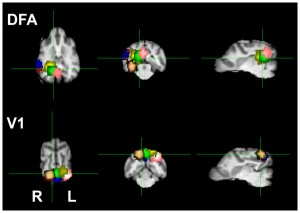
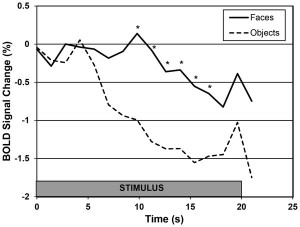
During the experiment, participating animals viewed still and motion pictures of facial and non-facial images while stationary within a 3-Tesla Siemens MRI scanner. The visual cortex of the animals activated whenever the dogs became attentive to an image. However, the FFA, dubbed the DFA (Dog Face Area) in the paper, exlusively activated when the dogs observed facial images. Interestingly, the DFA responded similarly to both human and canine faces, which elucidates how dogs respond brilliantly to human social cues communicated via facial countenance.
Although on the surface the preparatory process of teaching the dogs to watch movies may seem very simple, in actuality the experiment required multiple months of training. First, the dogs needed to become conditioned to the “hostile” variables common to the MRI environment, including the entry steps, the narrow patient table walkway, the narrow enclosure, and the 96 dB noise that encompasses multiple pitches and sequences. Moreover, the dogs must perform more than a typical down-stay. The dogs must perform a motionless down-stay, as movement greater than 2 mm within any spatial plane (vertical, horizontal, longitudinal, pitch, yaw) may render the image useless due to noise artifacts. Next, the dogs had to be conditioned to watch television without human accompaniment, as the experiment required that the dogs remain attentive to the screen for multiple 3-minute blocks.
For those interested in viewing a video of the training process, please link to the CPT Instructional Tips article from January 6, 2015, entitled “MRI Practice: Truffles Practicing for the ‘Danny Faces’ MRI Experiment.” For those wishing to learn more about the visual ability of dogs to watch televised images, please link to the CPT Tails article, entitled “Lili Learns Not to Bark at Dogs on the TV.” The prior link scientifically explains the differences between human and canine visual abilities and how the technical evolution of television sets has better enabled dogs to view broadcast images.
The Project Team wishes to thank the Office of Naval Research (ONR), which funded the project. We also wish to thank the human volunteers and their dogs without whose dedication the project would have been impossible: Cindy Keen (Jack), Patricia King (Kady), Nicole Zitron (Stella), Darlene Coyne (Zen), Marianne Ferraro (Eddie), and Cory and Anna Inman (Tallulah).
(Decatur, GA)
(Sandy Springs, GA)