CPT’s Mark Spivak, along with his Dog Project cohorts Peter Cook, Ashley Prichard, and Greg Berns, authored a paper published in the high impact factor journal Social Cognitive and Affective Neuroscience (SCAN). The article, entitled “Awake Canine fMRI Predicts Dogs’ Preference for Praise Versus Food,” examines the reward preference amongst an experimental group of pet dogs. The paper describes 3 separate but cohesive experiments, two that used functional magnetic resonance imaging (fMRI) and one that involved a field behavioral test.
Within the dog training industry, in vogue training philosophies and methodologies are often spawned by tainted idyllic vision and personal zeal, rather than empirical evidence supporting the superiority or efficacy of a particular method or technique. One of the popular beliefs amongst the category of trainers that passionately classifies themselves as “purely positive” or “R+” is that the inclusion of food is necessary to obtain and to sustain the attentiveness and motivation of a working or pet dog. Moreover, persons within the said group often espouse that failure to incorporate food is indicative of a harsh or non-positive training style. However, formal research data was lacking to confirm whether the aforementioned dogma (pun intended) is veritable or whether it is a widely held, albeit specious, myth.
Consequently, The Dog Project research team designed experiments that in an unbiased manner evaluated:
a) whether the participating dogs preferred social reward from the owner (visual and/or tactile contact plus verbal praise) or an appetitive reward (hot dogs in the MRI experiments and Pupperoni treats in the field experiment) delivered absent of social contact,
b) whether reward preference was constant or whether it varied based on satiation or deprivation, and
c) whether reward preference was affected by mood state.
The first experiment, dubbed “Experiment 6” by the research team, evaluated the dogs’ preference for food versus reward by first using practice sessions to condition the dogs to the relationship between a visual object and a subsequent outcome. The dogs learned that after observing a pink toy car for 10 seconds their hidden owner would come into view to praise them, after observing a blue toy horse for 10 seconds they would receive food mechanically from a “treat kabob,” and after observing a gray hairbrush for 10 seconds no significant outcome would occur (the control condition). Upon completing the preparatory conditioning process at CPT we scheduled the dogs for live MRIs at the Emory University Psychology Building. During the MRI sessions, we randomly exposed the dogs to 32 presentations of each conditioned stimulus. We then used Analysis of Functional Neuroimages (AFNI) software to determine the difference in hemodynamic response amongst each condition. The region of interest (ROI) was the nucleus acumbens, a section of the brain within the ventral striatum that is notable for its dopamine activity upon the anticipation of reward. Thus, the AFNI software would detect greater activation when the dogs were exposed to visual stimuli associated with higher perceived reward valuation.
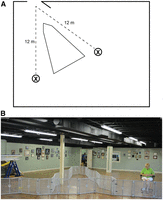
The second experiment, dubbed “Experiment 6b,” was a field experiment that presented each dog with practical applications of praise versus food options. We partitioned the CPT training floor with gates that when connected assumed the shape of a large Y. On the end of each partitioned hemisphere we located a reward- either a bowl of Pupperoni or the owner sitting in a chair. While the dog viewed the alignment of the room and the placement of each reward item, we conditioned the dog that if he/she progressed toward the owner he would receive praise and petting and that if he/she progressed toward the salient yellow bowl he would be allowed to devour the treat within the bowl. To account for the potential of side bias, we rotated the location of the reward (left vs. right) during each conditioning repetition and later during each experimental repetition. Upon the completion of the conditioning process, whereby the dog had sufficient opportunity to understand that both the owner and food were present in the room, we then sequestered the dog in the storage area, whereupon after a set interval we released the dog onto the segmented training floor to select amongst contact with the owner, eating the food, or doing nothing. Each dog completed a total of 20 trials, after which we statistically measured the dog’s preference and trends. To see insightful videos of Experiment 6b, please link to the CPT Tails article entitled, “The Dog Project: Experiment 6b- Reward Preference.”
The third experiment, dubbed “Experiment 7,” examined the phenomena of expectation violation. For the most part Experiment 7 duplicated Experiment 6. We used the same familiar conditioned stimuli within the MRI. However, we skewed the overall frequency of the objects, so that instead of viewing each object randomly for an equal number of trials the dogs viewed the horse and brush equally, but viewed the toy car approximately 5 times as frequently as it viewed the horse or brush (or 2.5 times as frequently as both stimuli combined). In addition, in 25% of the car presentations we purposely did not have the owner come into view after the dog observed the car. The failure to deliver the anticipated reward is formally called “expectation violation” or in less formal terms, “disappointment.”
In Experiment 6, the dogs consistently exhibited higher activation for both the car and the horse than for the brush, which showed that they understood the experiment and that they preferred both praise and food over receiving nothing. Nevertheless, the most significant finding was that ventral striatal activity empirically showed that a whopping 13 OF THE 15 DOGS SHOWED EQUAL OR GREATER VALUATION FOR PRAISE IN COMPARISON TO FOOD delivered in a nonsocial context. 4 strongly preferred praise, 9 were about equal in their preference, and 2 strongly preferred food.
www.washingtonpost.com/video/c/embed/4eb6183e-648f-11e6-b4d8-33e931b5a26d (click the preceding link to see a video edited by the Washington Post that shows Kady being trained for each of the conditioned stimuli)
In Experiment 6b, we found initially that in all but two cases the preferences exhibited in the scanner during Experiment 6 were paralleled during the field experiment. The two cases that ran contrary to form were very interesting. Two dogs that strongly preferred food in the scanner surprisingly almost unanimously preferred the owner during the 20 trials of the field experiment. The research team then got together and deduced why. The 2 dogs were also the most anxious of the 15 subject dogs. The subject dogs often exhibited anxiety when exposed to novel environments and when exposed to novel people. Therefore, the setup of Experiment 6b fostered an anxious emotional state, whereby the dogs temporally preferred the owner because at the time what the dogs desired most was security- and the owner provided more security from perceived threat than did the food. Consequently, we modified the conditioning format for the 2 dogs. We had the owners play with them in the storage room and had the experimenter, who held them during the interval periods, feed them treats and play with them both in the main training area and within the storage area. Once the dogs conspicuously became comfortable with both the storage area and the experimenter we repeated the 20 trials. When in a relaxed emotional state the dogs reverted to the norm they exhibited in the MRI, whereupon they demonstrated a strong preference for food. Thus, we learned that the MRI experiment accurately determined behavior and that reward preference can be affected by emotional state.
In addition, for the dogs that showed equivalent preference for praise or food, they tended to vary their choice temporally based on satiation or deprivation. In simple terms, they would go back and forth in selection either every other trial or after completing several of the same choice.
In Experiment 7, based on the neural activation in the ventral striatum, as expected, we observed anticipated reward when the dog witnessed the pink toy car and lower activation when the dog subsequently received nothing versus when the dog received the expected reward. Thus, the hemodynamic response indicated disappointment due to the expectation violation.
The Dog Project Team and CPT believe the combination of experiments and the resultant coverage of the findings should crucially alter accepted dog training methodologies. The paper received reporting and commentary in Science Magazine, Psychology Today, The Washington Post, and The AJC, amongst many esteemed media outlets.
Most significantly, we found that the correct reward system depends on the dog. Contrary to popular practice, there is not a single reward method that is optimal for all dogs, regardless of breed and regardless of gender. Some dogs prefer praise. Some dogs prefer food. More dogs prefer praise than prefer food. And the majority of dogs value each about equally overall, with which one they prefer at a given time affected principally by psychological or physical satiation or deprivation. Moreover, some dogs will alter preference based on exigencies. For instance, in Experiment 6b, when posed with the perception of threat and while in an anxious emotional state, dogs that typically preferred food instead preferred the owner.
Therefore, when constructing or implementing a dog training program, trainers and owners will maximize productivity by evaluating which reward system is optimal for the specific dog. For some dogs, handlers will optimize results by implementing a strong skew toward praise as the primary reinforcer. With a smaller subset of dogs handlers should implement a strong skew toward food. Yet, with a majority of dogs handlers should intermittently vary the primary reinforcer.
The data shows that although food is a valuable teaching tool during incipient training stages, as it provides extra clarity regarding whether a dog is correct, especially if an owner lacks competency at properly modulating his/her voice in a praise mood, in the long term emphasizing food as the sole primary reinforcer will fail to maximize attentiveness and motivation for a majority of dogs. Moreover, after training over 50,000 dogs and dog owners, we have seen at CPT that when food is emphasized for too long a period or administered too liberally the dog loses attentiveness and motivation. Furthermore, we have observed that when the trainer or owner emphasizes food for too long a period that the dog lacks optimal bonding with the person, the dog fails to develop proficient human-dog receptive communication skills, and the human fails to develop ideal human-dog expressive communication skills, since the human mistakenly delegates the communication and reward responsibility to the inanimate food object.
Consequently, for the majority of dogs, after the incipient learning stage, the trainer/owner needs to learn to impart effective praise communication and the handler needs to emphasize praise as the principal primary reinforcer or an equivalently delivered primary reinforcer in a random rotation with food. Only a minority of dogs should continue to receive food as the sole primary reinforcer. Moreover, when dogs are insecure, proximity, praise, and tactile contact from a calm, confident owner can be reassuring and significantly more valuable than food. Thus, when developing counterconditioning and desensitization programs that diminish anxious and/or aggressive behavior, trainers need to contemplate whether appropriate owner interaction may be more productive than food rewards in modifying a dog’s behavior.
(Sandy Springs, GA)
(Atlanta, GA)
(Decatur, GA)

Need to get in touch with CPT? I’ve got you covered.
Pick what works best for you!
























